Arquitetura Par-a-Par
Nesta seção, iremos comparar a arquitetura Par-a-Par com as características já conhecidas das dinâmicas cliente-servidor, além de explorar os diferentes modelos de se conectar uma rede P2P.
Diferenças entre arquitetura Par-a-Par e Cliente-Servidor
| Par-a-Par | Cliente-Servidor |
|---|---|
| A informação está distribuída | A informação fica concentrada |
| Um computador conecta-se com diversos pares | Um computador está limitado a se conectar com servidores |
| A transferência de informações estará ativa desde que existam nós na rede |
Quando um servidor está inoperante, as solicitações dos clientes não podem ser satisfeitas |
| Pares podem entrar e sair da rede sem debilitá-la | A troca de um servidor requer uma atualização em seu DNS |
| Não há nós com funções especiais, ou seja, todos os nós são iguais ou podem ter as mesmas funções |
As funções são bem delimitadas tanto para o servidor quanto para cada cliente |
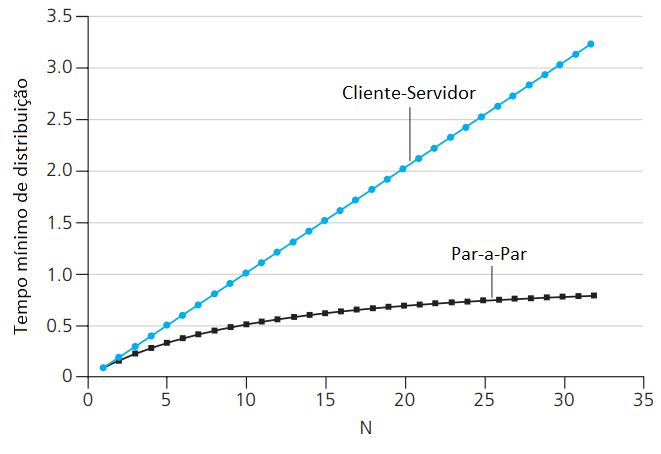
Abaixo, apresentamos um gráfico ilustrando a complexidade temporal da distribuição de conteúdo em ambas as arquiteturas. Enquanto um servidor sem técnicas de replicação possui uma distribuição serializada, as redes Par-a-Par possibilitam a obtenção de conteúdo e processamento a partir de diferentes nós da rede.
Arquitetura Par-a-Par e o Conceito de Rede Sobreposta
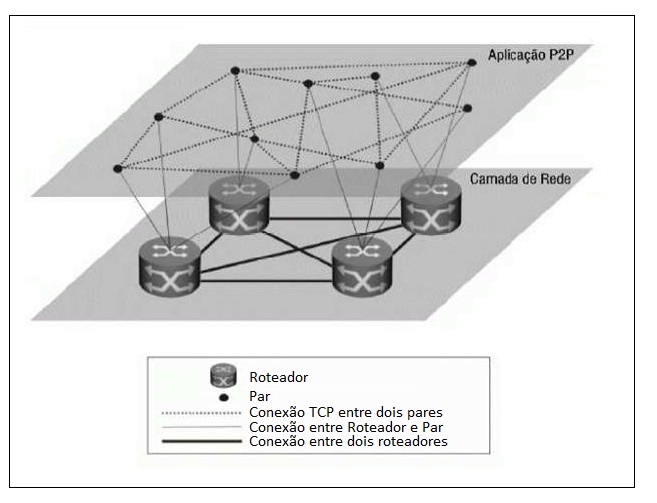
Para continuarmos a estudar a arquitetura Par-a-Par, é necessário compreender o conceito de redes sobrepostas. Provenientes do inglês "overlay networks", tais redes são construídas em cima de outras já existentes que, por sua vez, fornecem infraestrutura. Assim, um laço virtual entre dois nós de uma rede sobreposta pode corresponder, na verdade, a diversos outros laços da rede infraestrutural.
Este tipo de abstração é de grande relevância à arquitetura Par-a-Par por possibilitar que pares se encontrem e se reconheçam de forma independente da topologia física. Assim, ao representarmos uma conexão entre dois pares de uma rede P2P utilizando apenas uma aresta, estamos capturando apenas as informações que de fato são relevantes para a topologia da rede Par-a-Par, sem ser necessário levar em conta as rotas pelas quais os pacotes serão roteados. A imagem abaixo ilustra este conceito:
Assim, dedicamos duas das seções abaixo para tratar dos dois tipos de redes sobrepostas que são bastante encontrados na arquitetura Par-a-Par: as redes estruturadas e as não-estruturadas.
Redes sobrepostas não-estruturadas
As redes não-estruturadas não possuem uma estrutura definida na rede de sobreposição e não usam algoritmos específicos para organizar as conexões da rede, sendo que cada nó estabelece conexões aleatoriamente entre outros nós. A imagem abaixo ilustra e complementa essa definição, sinalizando pontos fortes e fracos:

Podemos ainda classificar as redes não-estruturadas em três tipos distintos, dependendo da maneira como a arquitetura P2P é utilizada:
- P2P pura: Nesta modalidade, a arquitetura é completamente descentralizada e não há um elemento central, sendo o completo oposto do modelo cliente-servidor. Todos os nós possuem papel equivalente e o sistema de busca é por inundação, gerando certas desvantagens. Exemplos são o Gnutella e o Freenet. Devido às desvantagens, aplicações P2P “puras” são raras e a maioria das arquiteturas P2P é híbrida, utilizando alguns elementos centralizadores na execução de tarefas cujo desempenho é mais crítico.
- P2P híbrida: Aqui, existem alguns nós especiais, chamados de supernós, que realizam ações de coordenação como conceder o ingresso dos nós na rede, indexar os dados compartilhados e liberar a busca por recursos que, quando localizados, podem ser trocados a partir da interação direta entre os nós convencionais. Dependendo da implementação, uma falha em um supernó pode ser tolerada de diversas formas, como, por exemplo, escolhendo-se um outro supernó. Exemplos de redes P2P híbridas são o Kazza e o Bittorrent.
- P2P centralizada: Apesar de serem redes híbridas, possuem verdadeiros servidores centrais que controlam as entradas e as saídas dos nós na rede, nos quais cada par deve registrar os recursos a serem compartilhados. As pesquisas por recursos disponíveis são executadas pelo servidor central, enquanto o acesso aos recursos é efetuado diretamente entre os pares no mesmo paradigma de transferência Par-a-Par. Exemplos desse paradigma centralizador são o eMule e o Napster.
Redes sobrepostas estruturadas
As redes estruturadas usam algoritmos e critérios específicos para organizar as conexões da rede. Sendo assim, possuem protocolos que garantem que qualquer nó possa encaminhar uma busca a outro nó que disponha do arquivo desejado. O procedimento mais utilizado é, em geral, uma implementação de tabelas hash distribuídas (DHT, do inglês Distributed Hash Tables), garantindo que qualquer nó possa buscar na rede um recurso ou arquivo de forma eficente, mesmo quando tal recurso for significativamente raro.
Algoritmos e Modelos
Nesta seção, entraremos em detalhes sobre as características das diferentes implementações de DHT, além de comentar sobre outras técnicas utilizadas em redes Par-a-Par.
Tabelas Hash Distribuídas (DHT)
Esta classe de sistema distribuído oferece uma forma de roteamento mais estruturada de modo a obter tanto descentralização quanto eficiência. Uma DHT é particularmente útil quando deseja-se criar um banco de dados distribuído de modo a alcançar maior escalabilidade.
Para atingir este objetivo, distribui-se tuplas de (chave, valor) entre os nós da rede de maneira que cada nó tenha posse de apenas um pequeno subconjunto de todas as tuplas (chave, valor) existentes. Assim, qualquer nó na rede, em posse de uma chave, poderá realizar uma consulta no banco de dados, que localizará os nós que possuem a tupla (chave, valor) correspondente e retornará a informação para o nó que iniciou a consulta. Precisamos, então, pensar em estratégias de identificar facilmente qual nó possui qual tupla.
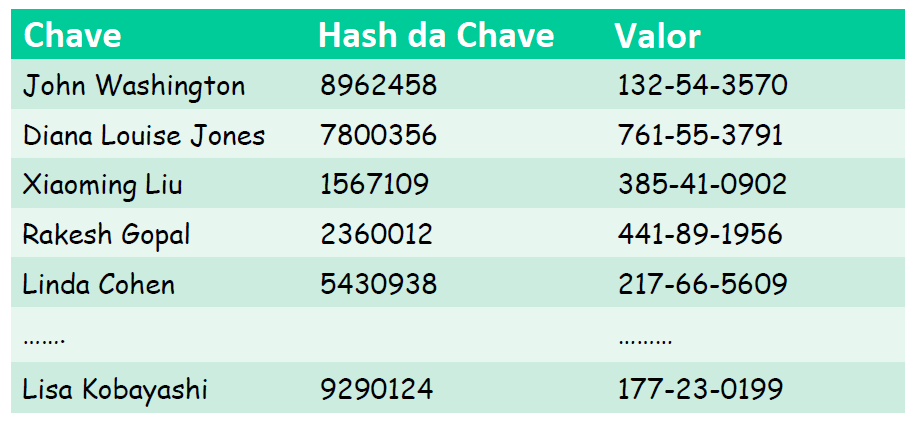
Uma abordagem ingênua e não escalável para se criar o banco de dados seria fazer com que cada nó mantivesse uma lista dos endereços IP de todos os nós participantes da rede. No entanto, isto exigiria que cada nó individual rastreasse todos os outros, quebrando a ideia de conectividade ad-hoc. Logo, uma abordagem mais efetiva seria atribuir um identificador a cada nó da rede, em que cada ID seria um número inteiro de 0 a 2(n-1). Se distribuirmos as tuplas (chave, valor) de modo que cada nó receba uma tupla apenas se seu ID for o mais próximo de um hash da chave correspondente, poderemos encontrá-lo mais facilmente no futuro. A tabela abaixo exemplifica os diferentes campos de informação existentes.
De fato, a abordagem descrita acima é amplamente utilizada nos sistemas de DHT. Vamos ver agora um exemplo em que os pares (chave, valor) serão distribuídos de acordo com a seguinte regra: um par (K, valor) será dado para o nó J, em que J é o sucessor imediato do resultado do hash de K. Para ilustrar, suponha um espaço de ID {0, 1, 2, 3, ..., 63}. Os 8 nós da rede possuem os IDs 1, 12, 13, 25, 32, 40, 48, 60. Se o hash da chave for 51, iremos dar sua tupla (chave, valor) ao nó 60. Se o hash da chave for 60, sua tupla também irá para o nó 60. Se for 61, daremos a tupla para o nó 1. Este é apenas um exemplo, podendo existir diferentes outras regras de atribuição que irão depender da implementação.
Uma das arquiteturas mais famosas das DHTs é a da topologia em anel, da qual deriva-se o nome Tabelas Hash Distribuídas Circulares. Aqui, cada nó apenas mantém uma rota para seu sucessor e seu antecessor imediatos. A figura A abaixo ilustra esta ideia, enquanto a figura B já começa a dar uma ideia de como este sistema pode ser melhorado:
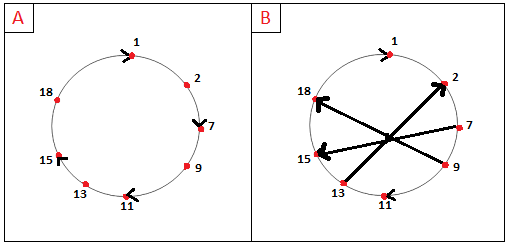
Por exemplo, na figura A, suponha que o nó 7 deseja se comunicar com o nó responsável pela chave 15, a fim de inserir ou consultar uma tupla (chave, valor). Usando a sobreposição circular, o nó 7 envia uma mensagem para o seu sucessor imediato (nó 9), perguntando quem é o responsável pela chave 15. Como o nó 9 não é o responsável pela chave 15, ele repassa a mensagem para o seu sucessor imediato. Assim, a DHT circular fornece uma alternativa para reduzir a quantidade de informações de sobreposição que cada nó deve gerenciar.
Porém, essa solução apresenta outro problema: para encontrar o nó responsável por uma determinada chave, no pior dos casos, todos os N nós da DHT terão que encaminhar uma mensagem ao redor do círculo. A fim de melhorar esta arquitetura, podemos adicionar atalhos para que cada par não acompanhe apenas os seus vizinhos imediatos, mas também um número pequeno de "pares-atalhos" espalhados pelo círculo (figura B). Desta forma, reduzimos consideravelmente o número de mensagens usadas para processar uma consulta (no exemplo, o nó 7 falaria diretamente com o nó 15, diminuindo substancialmente o uso de recursos por mensagem).
Diretório Centralizado
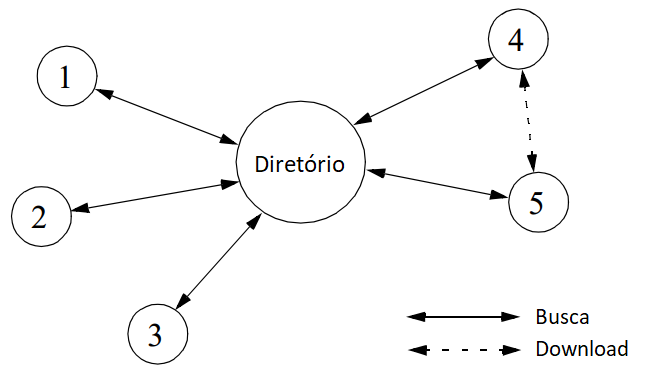
Neste modelo, os pares da rede se conectam a um diretório central onde publicam informações sobre o conteúdo que oferecem. Quando um nó realiza um pedido, o diretório central responde à solicitação associando a requisição ao melhor nó do diretório que o corresponde. Esta escolha de melhor nó é feita utilizando uma métrica que pode levar em conta o custo, a velocidade ou a disponibilidade de cada par.
Uma aplicação deste paradigma é o Napster, um serviço de música online P2P encerrado em 2002. Devido ao fato de requerer um servidor de diretório para fins de gerenciamento (como hospedar informações dos participantes), este modelo pode ser classificado como uma rede híbrida. Sendo assim, sua escalabilidade fica comprometida devido à necessidade de servidores maiores e mais robustos para cumprir a demanda à medida que o número de usuários aumenta.
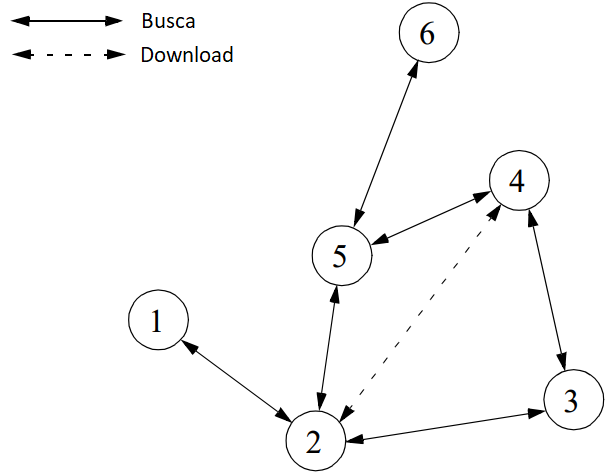
Busca por Inundação
Em contraste com o modelo de Diretório Centralizado descrito acima, a Busca por Inundação pode ser considerada P2P pura. Neste caso, não há um sistema central de gerenciamento que anuncia o compartilhamento de recursos. A busca por determinado arquivo é realizada enviando-se uma mensagem a todos os nós adjacentes. Tais vizinhos também enviam recursivamente uma mensagem aos demais nós conectados a eles, até que um número máximo de saltos (TTL) seja alcançado.
Notamos que este modelo também não é muito escalável, já que a requisição de dados causa muito tráfego de sinalização sem haver garantias de que o arquivo solicitado será encontrado. Por outro lado, se o objetivo do sistema é alcançar todos os nós da rede ou obter conteúdos raros (compartilhados entre poucos nós), este modelo mostra-se eficaz desde que o TTL da implementação seja suficientemente elevado.
Roteamento de Documento
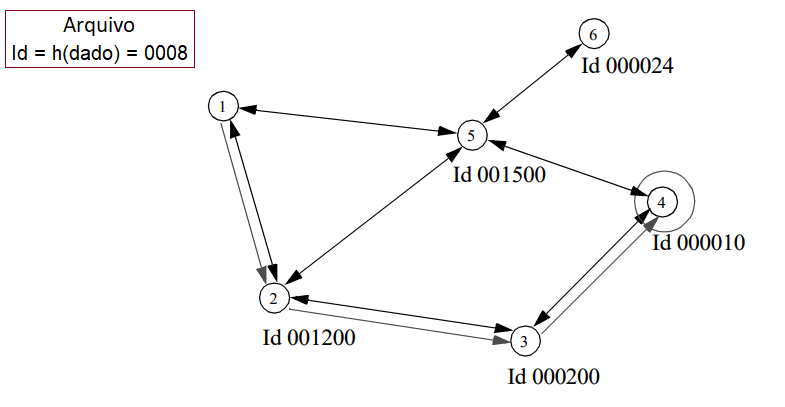
Trata-se de uma abordagem mais recente, adotada por aplicações como a FreeNet (uma plataforma par-a-par de comunicação anti-censura) que também objetiva o compartilhamento de arquivos. Este modelo funciona atribuindo-se um ID aleatório a cada par presente na rede, além de garantir que cada par também saiba o número de uma certa quantidade de outros pares. Um documento ou arquivo compartilhado, por sua vez, também possui um ID, baseado em uma função Hash aplicada ao seu nome e ao seu conteúdo. O arquivo será, então, roteado por cada nó buscando sempre o vizinho cujo ID possua a maior semelhança com o ID do arquivo. Este processo de roteamento é repetido até que o arquivo "chegue" ao par de ID mais próximo. É importante destacar que, a cada operação de roteamento, é reservada uma cópia local do arquivo em cada par participante da rota.
O processo de busca é análogo ao de armazenar um arquivo recém compartilhado na rede. Assim, o pedido é direcionado ao par cujo ID é o mais semelhante ao ID do arquivo desejado. Isto é repetido até que o conteúdo seja encontrado e enviado ao nó que realizou a solicitação. A necessidade de se conhecer o ID do documento de antemão torna a busca mais complicada do que, por exemplo, no modelo de inundação, mas o número de mensagens de controle é significativamente menor.