3. Navegação na Deep Web
3.1 Navegabilidade e Busca
Diversas páginas da Deep Web podem ser acessadas por meios idênticos a páginas mais convencionais da Surface Web, com a principal diferença que parte de seu conteúdo é gerado dinamicamente. Em prática, funcionam como páginas comuns que maioria dos usuários da web de superfície estão habituados. Porém, devido a sua natureza dinâmica, estas páginas não conseguem ser facilmente indexadas e, portanto, não são encontradas por motores de busca.
O funcionamento de motores de busca é baseado na construção de um banco de dados através de programas denominados web crawlers, ou spiders (aranhas), que partem de uma lista de páginas da Internet conhecidas. A Deep Web é composta, justamente, das páginas que não conseguem ser encontradas por web crawlers.
Algumas páginas, contudo, podem requerer um software adicional para acesso. Como exemplo, temos as páginas hospedadas dentro da rede TOR que requerem um software específico para serem acessadas. Esta parte da Deep Web que garante o anonimato é conhecida, então, como a Dark Web.
Figura 4: Printscreen do Navegador TOR
Fonte: securityinabox.org/pt/guide/torbrowser/linux (acessado em 02/06/19)
3.2 Invisibilidade na Rede: Como TOR Funciona
O anonimato dos usuários é um foco maior para a Dark Web do que para a própria Deep Web, acessível por navegadores convencionais. Cada Darknet tem sua forma específica para manter o anonimato. A rede TOR, por exemplo, usa um sistema de camadas denominado Onion Routing (roteamento cebola), onde os dados são encriptados sucessivamente (incluindo o endereço IP do próximo nó) e enviados a um ponto da rede escolhido aleatoriamente. Este ponto descriptografa parte dos dados, para saber qual o próximo ponto que deverá enviar os dados. Sendo descriptografados, sucessivamente, até chegar na última camada, que envia os dados para o destinatário sem saber a fonte de tais dados.
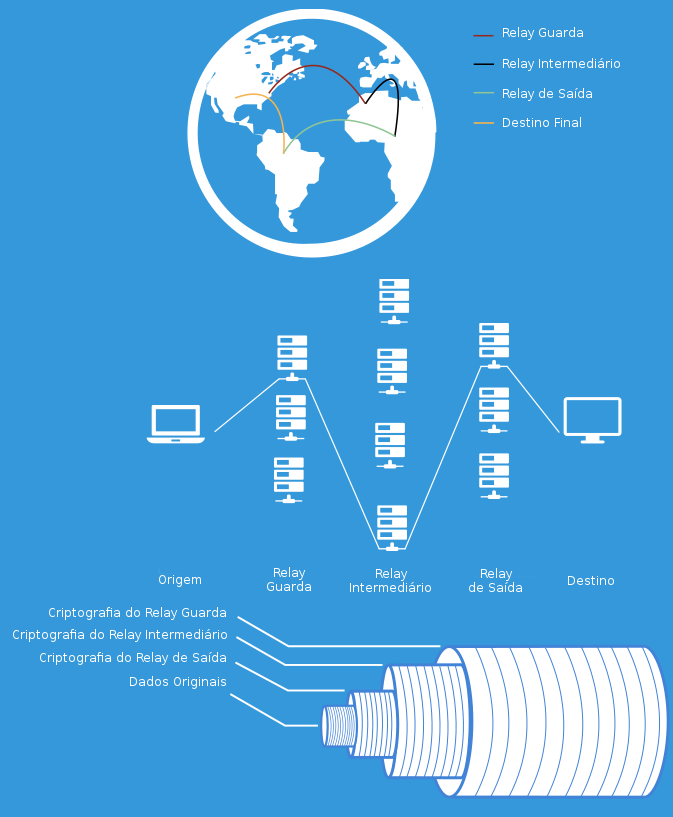
Figura 5: “The Onion Routing” (TOR)
Fonte: WRIGHT, Jordan. "How Tor Works". 2015.
O funcionamento do The Onion Routing (ou TOR) se baseia na ideia de que seu computador, ao utilizar o TOR, escolhe três relays (ou nós) para encaminharem seu tráfego de forma que ele saia para a Internet com o IP do último deles, o relay de saída. Sendo assim, ao enviar uma mensagem ou acessar uma página através do TOR, seu conteúdo é enviado com três camadas de criptografia, uma para cada relay. Como o número de relays existentes na rede TOR são cerca de 7.200 (informação de 2016) e mais de 2 milhões de pessoas utilizando o serviço, há o efeito de anonimizar a sua conexão, impedindo que os pacotes de dados sejam ligados ao seu endereço IP - tanto pelo provedor de conexão quanto pelo serviço acessado.
O relay guarda sabe que determinado IP usou a rede TOR, mas não sabe o motivo. O relay intermediário não tem acesso ao conteúdo, remetente nem ao destinatário. Finalmente, o relay de saída sabe apenas o destinatário e o conteúdo, sendo responsável por encaminhar o pacote para a "Internet aberta". E ainda, se há uso de criptografia entre remetente e destinatário, comum em grande parte dos serviços na Internet, o relay de saída também não saberá o conteúdo do acesso ou comunicação.
O mapa abaixo lista a quantidade e localização de relays de saída/retransmissão geograficamente distribuídos da rede TOR, disponibilizada de maneira pública pelo site Blutmagie.
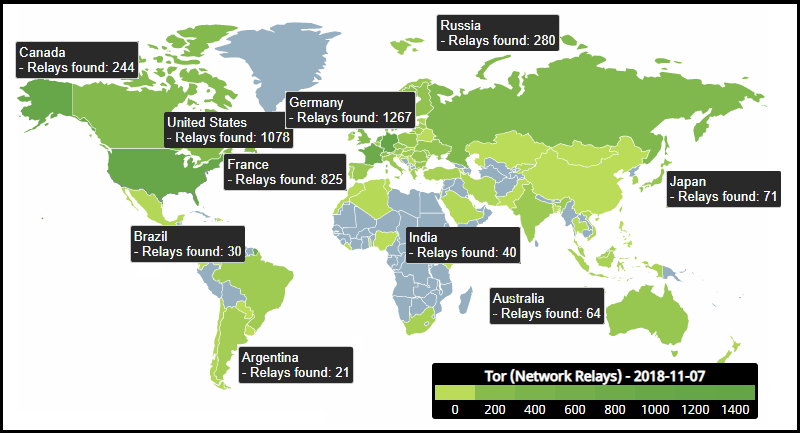
Figura 6: Relays de Saída do TOR Mapeados
Fonte: coderi.com.br (acessado em 02/06/19)