![]()
![]()
![]()
![]()
![]()
![]()
![]()
Topologia
Hoje em dia, as arquiteturas de topologia consistem basicamente em dois ou três níveis de Switches ou roteadores. Para entendermos melhor temos a figura acima. Ela possui um nó núcleo (core tier) na raiz, um nó de agregação (Agregation tier) no meio, e um “nó termino” (edge tier).
Um design de dois nós possui somente o nó raiz e nós término. Tipicamente, este nó consegue comportar de 5 K à 8 K estações. Para redes maiores de cerca de 25 k estações devemos optar pela formação de três níveis, a qual iremos mais a fundo. Switches, neste contexto, são todos os dispositivos que atuam na camada física e de roteamento. Uma vez inseridos nas folhas da árvore, produzem portas (48-288) GigE (Gigabit Ethernet), assim como 10 GigE uplinks. Estes dispositivos atuam em uma ou mais elementos da camada da rede que agregam e fazem a transferência de pacotes entre as folhas-switches. Em hierarquias de mais alto nível existem switches com 10 portas GigE (tipicamente de 32-128) e significante capacidade de agregar tráfego entre os términos(edge).
Podemos ressaltar dois tipos de switches que representam um high-end em ambos densidade de porta e largura de banda. O primeiro, usado em término(edge) é conhecido como 48-portGigE com 10GigE uplinks. Para maiores níveis de hierarquia de comunicação utiliza-se 128 ports 10 GigE. Todos os dois switches permitem conexão com o host em todas as direções para comunicação entre si à velocidade total de suas interfaces.
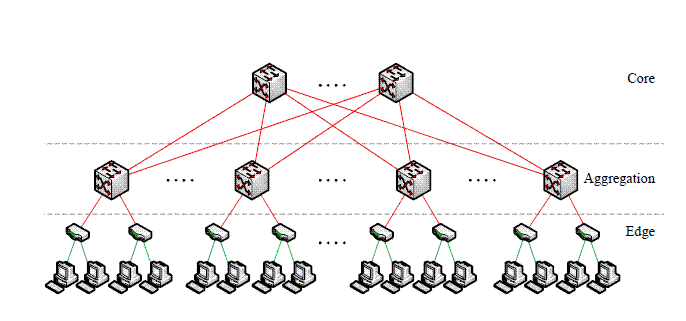
Fat tree
A k-ary Fat tree é a topologia mais utilizada em data centers por sua maior eficiência. A principal característica que difere uma Fat-tree de um árvore comum é a disposições de suas conexões. Enquanto que numa árvore computacional o links ficam numerosos à medida que vão existindo filhos, na fat-tree os links se tornam mais numerosos “fatter” a medida que se direcionam à raiz. Esta topologia foi desenvolvida por Charles Clos do MIT, para obter altos níveis de banda passante para vários dispositivos, apropriadamente interconectados com switchs menores.
Na figura acima a Fat tree é composta da seguinte maneira. Existem k ramos, cada um contendo 2 camadas que, por sua vez, possui k/2 switches. Cada switch intermediário conecta-se com 2 switches da camada inferior e com todos switchs do core. Na camada Edge, ocorre a conexão entre os hosts e o switch de término(TOR).
Separação identificador/localizador.
Um conceito muito importante que diverge a rede de um data center da Internet é questão do endereçamento IP. Diferentemente da Internet, ocorre uma divisão entre identificador e localizador tendo como papel fundamental de permitir o compartilhamento de recursos dos serviços com o endereçamento IP. O IP é usado para identificar servidores físicos (e virtuais) dentro do Data Center, ou seja, não são impostas restrições de como os endereços são atribuídos ou utilizados para acesso externo (Internet). Não são significativos para o roteamento de pacotes.
Problemas para o roteamento.
Para atingir a máxima banda bidirecional, a rede demanda tráfego de saída espalhado de qualquer ramo que eventualmente seja possível para os switches. Protocolos de roteamento como OSPF geralmente utilizam-se de contagem de hop para sua métrica de “shortestpaht”(melhor caminho sempre é o mais curto). Na k-ary fat tree existem (k/2)^2 “menores caminhos” entre qualquer dois host de diferentes ramos, porém somente um é o escolhido. Dessa maneira, switches concentram o tráfego de saída para um subnet através de uma única porta, apesar de outras rotas existirem e “custarem” o mesmo valor. Além disso, dependendo do intervalo de chegada das mensagens OSPF, é possível que apenas um dos switches do core, ou alguns poucos, sejam responsáveis por intermediar todos os links entre os ramos. Isto pode causar congestionamento severo para aqueles que não se fazem valer da vantagens da redundância.
Qualquer host precisa realizar o seguinte caminho: acessar o switch do Core para depois acessar o switch na camada edge e o host desejado, sempre passando por switchers intermediários.
Rota na origem.
Esta abordagem permite enviar pacotes por rotas diferentes (balanceamento de carga), além de permitir a seleção da rota menos congestionada (engenharia de tráfego).
A especificação da rota na origem é baseada na utilização do filtro de Bloom nos pacotes (iBF - in-packet Bloom filter) contendo apenas três elementos identificadores de switches Core; Aggr(desce.); ToR(destino). O identificador utilizado corresponde ao endereço MAC do switch.
O esquema básico adotado para operacionalização do filtro de Bloom consiste na programação do ToR para adicionar, nos campos src-MAC e dst-MAC do cabeçalho do quadro Ethernet, o filtro de Bloom contendo a rota. Na seqüência, o ToR encaminha o quadro para o Aggr de subida. Deve ser ressaltado que não há necessidade de incluir o identificador do Aggr de subida no filtro de Bloom já que esta informação é implícita ao ToR. Nos próximos saltos, apenas três encaminhamentos são realizados utilizando o iBF, conforme exemplificado na Figura 2.

Filtro de Bloom
Um filtro de Bloom é uma estrutura de dados que identifica se determinado elemento está ou não presente nessa estrutura. É implementado como um vetor de m bits, com n elementos inseridos por k funções de hash independentes. Cada elemento, ao ser inserido no filtro, passa por uma função de hash cuja ação consiste na atribuição do valor 1 ao bit na posição do vetor associada ao resultado do hashing. Para verificar se algum elemento está presente, os resultados de todas as k funções de hash devem possuir o valor 1 no vetor. Basta um único dos bits anteriores apresentar o valor zero para concluir que o elemento não está presente. Neste caso, não há possibilidade da ocorrência de falsos negativos. Um falso positivo ocorre quando todos os resultados das k funções de hash em um elemento, que não foi inserido, apresentam o valor 1.
Serviço de Topologia -Protocolo de descoberta
Para que se possa utilizar tanto o filtro blom, como o rack mangment, ao qual vamos detalhar mais a frente, e ter um perfeito funcionamento do sistema é necessário saber a topologia da rede. Como sistema requer escalabilidade e não pode sofrer inundações causadas pelo propagação de pacotes, o ARP possui sua função limitada. Em contra-partida o protocolo LLDP – Link Layer Discovey Protocol é utilizado. Este protocolo busca a informação na rede e as guarda em banco de dados do sistema e pode ser acessado através do protocolo SNMP.
Novo Estudo
Universidade da Califórnia em San Diego, através de três de seus alunos, Mohammad Al-Fares, Alexander Loukissas and Amin Vahdat, realizou um estudo propondo um rearranjo de protocolos de topologia de modo que à mesma fat tree, antes mencionada, possa utilizar uma banda com plena capacidade de banda e velocidae (10 GigE) para todos os seus end-host. Uma das considerações por parte dos autores é tecnologia x custo. Entretanto o cenário observado por eles é outro. A Internet vem aumentando demasiadamente e com ela as técnicas e tecnologias, porém o inter-domínio não.
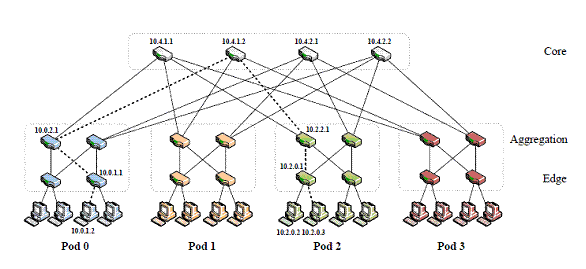
Uma característica, entretanto, bastante interessante é rearranjo da fat-tree e a tabela de dois níveis nos roteadores.

A figura acima representa a fat-tree reformulada da seguinte maneira. Existem k pod, cada um contendo 2 camadas que, por sua vez, possui k/2 switches (camada de Agregação e camada de Edge). Na camada edge, cada “porta-k” de um switch é conectado com k/2 hosts do seu respectivo pod. O restante das portas k/2 são conectados em k/2 das k portas da camada de agregação.
Existem cerca de (k/2)^2 k-portas no switches de núcleo. Cada switch núcleo possui uma porta ligada a cada pod. Em geral, cada árvore comporta (k^3)/4 hosts.
Como IP estão arranjados
Todos os IP são alocados no bloco 10.0.0.0/8.
Condições:
Os switches de agregação e edge recebem o endereço da seguinte maneira 10.pod.switch.1 onde, “pod” será o número do pod ([0,K-1]); e o “switch” será a posição do switch ([0,k-1], começando da esquerda para direita, de cima para baixo).
Já os switches de núcleo recebem endereços da forma 10,k,j,i onde j e i denotam as coordenadas na grade (k/2)^2 ( [1,(k/2)] começando do topo para esquerda).
Os host recebem a seguinte configuração 10.pod.switch.ID ([2,k/2+1] começando da esquerda para a direita).
Dessa maneira, cada switch da última camada é responsável por /24 sub-rede de k/2 hosts ( sendo k<256). Na figura acima temos a ilustração de como isso é feito.
Tabela de roteamento de dois Níveis.
Para prover distribuição igual, muda-se a tabela de roteamento para permitir dois níveis de prefixos de “lookup”(busca). Cada entrada na tabela principal terá, pontencialmente, um ponteiro para adicional pra uma segunda tabela de (sufixo, porta) de entradas. A tabela não terá obrigatoriamente ponteiros para segunda tabela, basta existir um pré-fixo de terminação pra indicar que não existe. Por outro lado, cada tabela secundária poderá receber mais de um ponteiro.
A figura acima contém a tabela do switch 10.2.2.1. Supondo que ele recebe pacotes para o switch 10.0.1.2 para o host 10.2.0.3. Os switch sabem que deve procurar o pond 2 devido ao seu endereço. Ao chegar em um switch de agregação, ele procura em sua tabela a sub-rede como mostra a tabela. A encontrar a sub-rede ele referência a porta do próximo switch e é repassado pela porta 1.
Este processo sofre uma penalidade de processamento de ordem marginal, entretanto é compensando pelo hardware, uma vez que este utiliza a CAM ( Content-Addressable Memory) para fazer comparações em binário.