A Surface Web, internet que usamos diariamente, é indexada por mecanismos de pesquisa (como o Google). Essa indexação ocorreu de maneiras diferentes ao longo do tempo, como o rankeamento pelo número de palavras num site associadas a um determinado contexto, ou o número de links que referenciam determinado site. Hoje, a importância de um site (e o quão na “superfície” ele se encontra) é ditada por algoritmos recursivos que dão peso à referenciação (quanto mais referências uma página detém, mais importância terão as páginas as quais ela referenciar).
A Deep Web, no entanto, não é externamente indexada. Seu conteúdo não se encontra disponível em sites ou páginas estáticas, mas sim em bancos de dados que dinamicamente respondem a requisições específicas. Isso significa que sites na Deep Web podem dinamicamente decidir quais links e/ou conteúdo serão disponibilizados à cada usuário, garantindo a privacidade de ambas as partes.
Essa característica dos sites da Deep Web, de disponibilizarem links dinamicamente de acordo com a requisição, a torna um agrupamento de vários conjuntos de redes individuais. Na verdade, cada usuário vê esse agrupamento de conjuntos de maneira diferente, já que as relações entre domínios se modificam autonomamente.
Dessa maneira, vê-se a dificuldade de mapear ou mensurar a Deep Web. A tecnologia de crawlers empregada hoje na rede indexada é absolutamente ineficaz no ambiente em questão, já que eles teriam que montar queries para caminhos específicos, mas sem saber como montar essa query em primeiro lugar (precisariam essencialmente ver o futuro).
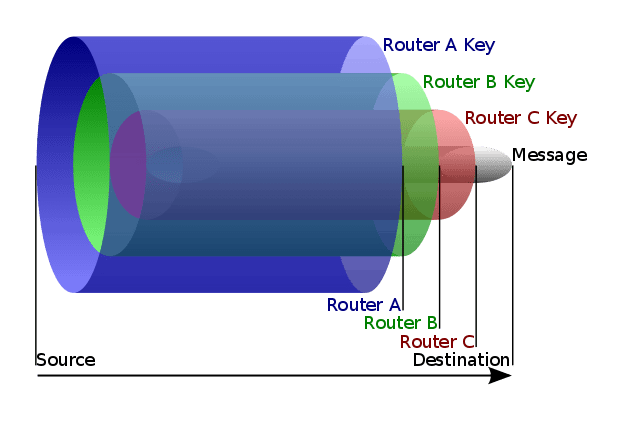
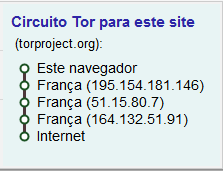
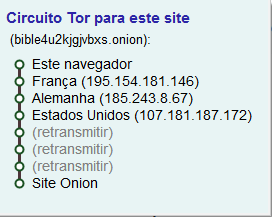
A garantia de privacidade na Deep Web é extremamente importante para seus usuários, assim como veremos de forma mais aprofundada na seção "Privacidade e Segurança". Por causa dela, além de toda a questão da responsividade dinâmica oferecida pelos domínios das redes nesse ambiente, o próprio roteamento deve oferecer anonimato. Uma solução bastante conhecida é o TOR (The Onion Router), que é o roteamento em camadas. Os pacotes de dados são encriptados em camadas, e cada dispositivo desencripta (ou sabe desencriptar) somente sua respectiva camada. Em cada uma dessas respectivas camadas por dispositivo, está o endereço apenas do próximo dispositivo do roteamento. O que acontece é que cada dispositivo sabe endereços apenas dos saltos imediatamente antes e após de si mesmo - não é conhecida a origem dos pacotes ou seu destino final.