O conceito de Cidade Inteligente abrange diversos setores de uma cidade e agrega a utilização de diversas tecnologias. Atualmente a transformação de uma cidade em inteligente só é possível através de campos da Engenharia, como Big Data e Internet das Coisas, bem como conceitos que surgiram em conjunto dos avanços tecnológico e novas possibilidades de uso da tecnologia, por exemplo, Dados Abertos e e-Government.
Dados Abertos
Dados Abertos procuram disponibilizar a informação digital de forma gratuita, sendo possível a sua modificação, compartilhamento e reutilização. Atualmente, este conceito vêm sendo muito explorado por governos, que abrem os seus dados para qualquer tipo de consulta ou análise.
Iniciativas como essa permitem que cidadãos comuns possam utilizar dados outrora inúteis para gerar informações relevantes. Esse empoderamento social cria um novo tipo de cidadania digital, que permite que a inovação se dê a partir da sabedoria da massa. Essa inovação retroalimenta o ciclo das cidades inteligentes, trazendo novas informações a serem analisadas, permitindo assim tomadas de decisões melhor informadas e uma consequente melhora na cidade.
Internet das Coisas
A evolução recente do conceito de Internet das Coisas (abreviada como IoT, do inglês Internet of Things) pode ser acompanhada com o crescimento da conexão em rede, do aumento do número de sensores e do barateamento de dispositivos que se tornaram de uso habitual da população, usando protocolos adequados com a capacidade de se comunicar uns com os outros e com os usuários. O valor de Internet das Coisas no contexto de Cidades Inteligentes está em permitir a obtenção de dados de uma forma cada vez mais eficiente, visto a crescente presença desses aparelhos. Este poder de adquirir, transmitir e analisar dados pode se relacionar com o aumento na capacidade de processamento de informação que exemplificaremos na seção Big Data.
O uso de mais dispositivos forma uma grande rede de informações que possibilita um aprimoramento da tomada de ações decisivas dentro de uma Cidade Inteligente. Na parte técnica, uma das questões relevante é a comunicação entre as tecnologias heterogêneas usadas nas cidades e centros urbanos. Situações do uso em massa desse recurso pode ser observado com o aplicativo de tráfego inteligente Waze, onde de forma colaborativa os usuários fornecem dados sobre a condição do trânsito buscando rotas alternativas. Essa informação é utilizada dentro do aplicativo e exportadas para canais externos a partir de parcerias específicas dentro do projeto Waze Connected Citizens, que será melhor abordado no Estudo de Caso sobre o Rio de Janeiro.
A principal característica de uma infraestrutura da chamada Internet das Coisas é a sua capacidade de integrar diferentes tecnologias. A abordagem de serviço web para a concepção de serviços IoT exige a implantação de camadas de protocolo adequados nos diferentes elementos da rede. O setor da industria já está em produção de dispositivos que se aproveitam das tecnologias para permitir as aplicações de interesse e existem diversas opções para a implementação de sistemas IoT, mas poucas delas utilizam protocolos abertos e padronizados.
Em [17], os autores apresentam uma aquitetura para o uso de Internet das Coisas para Cidades Inteligentes, com o nome de urban IoT, que é semelhante à já utilizada na Web. Para isso, adota-se um paradigma chamado Representational State Transfer (ReST), ou, em uma tradução livre, Transferência de Estado Representacional. Usar a mesma abordagem da Web tem a vantagem de facilitar a adoção e o uso de IoT por desenvolvedores, que podem reutilizar conhecimentos previamente adquiridos, além de reaproveitar a vasta literatura existente sobre o assunto.
A arquitetura proposta é abstraída em três camadas principais: formato de dados, aplicação e transporte, e camada de rede. Na imagem abaixo, retirada do artigo, são enumerados os protocolos de cada camada, tanto em uma pilha de protocolos de baixa complexidade (constrained, ou restrito) e de alta complexidade (unconstrained, irrestrito).
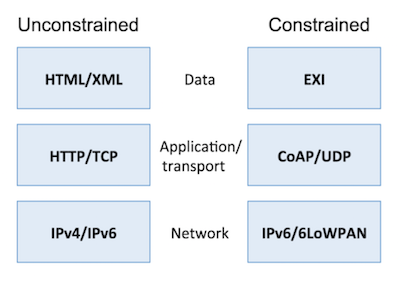
Figura 3.1: A primeira pilha ("irrestrita") consiste dos protocolos que são os padrões de comunicação na Internet hoje, enquanto a segunda pilha consiste dos padrões de baixa complexidade que teriam usos equivalentes para dispositivos com poucos recursos ("restritos").
Fonte: Zanella, A. et al. Internet of Things for Smart Cities. IEEE Internet of Things Journal, v. 1, n. 1, p. 26, 2014.
Na camada de formato de dados, no qual o eXtensible Markup Language (XML) é visto como o mais comum, devido a troca de dados ser normalmente utilizada com descrições do conteúdo através de meios de linguagens de representação semântica. Porém o tamanho das mensagens criadas pelo XML é grande, excedendo a capacidade normal de muitos dos nós de sistema IoT. Buscando um formato que pudesse suportar as mensagens XML mesmo em nós com extremas restrições, a W3C (World Wide Web Consortium) propôs o uso do Efficient XML Interchange (EXI).
O EXI define dois tipos de codificação, schema-less e schema-informed. A codificação schema-less tem origem diretamente dos dados XML e é capaz de ser decodificado por qualquer entidade EXI, sem conhecimento sobre os dados, enquanto a codificação schema-infromed assume que os dois processadores EXI tenham, previamente à codificação e descodificação, compartilhado um schema XML. Esse schema compartilhado torna possível atribuir identificadores numéricos para chaves XML no schema e implementa a gramática EXI durante a codificação. Um processador EXI de uso geral pode ser integrado mesmo em dispositivos com extremas restrições computacionais, tornando possível que esses dispositivos tenham a capacidade de interpretar formatos EXI e criando a possibilidade de se tornar nós IoT universais.
Na camada de aplicação e transporte, atualmente temos a maior parte do tráfego de dados na Internet sendo realizada via HTTP sobre TCP. Portanto, HTTP pareceria a escolha mais natural para a transferência de dados dentro de Internet das Coisas. Infelizmente, a aplicação direta de HTTP neste contexto é impedida pelas restrições computacionais e de processamento de alguns nós de IoT, além do protocolo de transporte TCP produzir um baixo desempenho em ambientes com perdas. O protocolo CoAP supera essas dificuldades, propondo um formato binário transportado sobre UDP, manipulando unicamente as retransmissões estritamente necessárias para fornecer um serviço confiável. Além disso, CoAP pode facilmente interoperar com HTTP, porque ele suporta os métodos ReST do HTTP (GET, PUT, POST e DELETE), e os códigos de resposta dos dois protocolos estão em correspondência um-para-um.
IPv4 é um dos lideres em tecnologia de endereçamento com suporte dos hosts da internet, porém com o esgotamento dos endereços do IPv4, ele não pode sequer ser considerado para Internet das Coisas. A solução óbvia seria o uso de IPv6, que, fornecendo o uso de 128 bits no campo de endereço, permitiria a atribuição de um endereço para cada nó na rede sem maiores problemas. Entretando, os overheads não compatíveis com os recursos escassos de alguns dos nós da rede impossibilita que IPv6 seja o padrão único da IoT.
Visando solucionar esse problema foi adotado o padrão 6LoWPAN, um formato de compressão de cabeçalhos IPv6 e UDP sobre redes de baixa potência e mais restritas, funcionando na base da conversão entre IPv6 e 6LoWPAN, traduzindo pacotes IPv6 com destino a nós da rede 6LoWPAN em pacotes com cabeçalhos compressos em formato 6LoWPAN, e traduzindo de forma inversa caso a operação seja o contrário.
Análise através de métodos de Big Data
Dentro do âmbito de Cidades Inteligentes, a geração de dados ocorre em volumes muito grandes e com alta frequência, fazendo com que seja impensável a utilização do modelo tradicional para a análise desses dados; o tempo necessário para que alguma conclusão fosse tirada seria superior à vida útil daquela informação. Entretanto, o crescimento e a intensificação do uso de técnicas de Big Data permite que plataformas como Hadoop (2011) e Spark (2014), que utilizam o poder do processamento paralelo, sejam utilizados para tornar esta análise possível.
Essas tecnologias são necessárias por causa de uma limitação física da Lei de Moore; a observação de que o número de transistores em um circuito integrado dobra em aproximadamente dois anos (sem aumento correspondente de custo) nada diz sobre a dissipação do calor produzido nesse circuito. Sendo assim, a saída para o aumento de poder computacional na última década tem sido a paralelização: Ao invés do núcleo do processador ser muito mais potente, mais núcleos são colocados. Entretanto, a programação paralela se torna muito complicada se deixada completamente a critério do programador. Tecnologias como as mencionadas acima auxiliam nessa tarefa, não só sendo plataformas que permitem que os vários núcleos de um mesmo computador sejam utilizados, mas também permitindo que o processamento seja dividido entre vários computadores. Sendo assim, podemos dispôr de muito mais poder computacional, e consequentemente analisar um volume muito maior de dados com muito mais velocidade.
Os softwares utilizados trabalham em cima de um novo Sistema de Arquivos chamado HDFS (Hadoop Distributed File System), voltado para a manipulação de grandes arquivos e para atender a diversos requisitos de um modelo de computação paralela, como ser mais tolerante a falhas e permitir uma recuperação rápida quando ocorrer alguma falha grave, além de ser preparado para trabalhar com clusters. Dessa forma, o HDFS possui uma distribuição em blocos contando com blocos de redundância para aumentar sua confiabilidade. Isso é necessário porque o aumento da probabilidade de um dos nós falhar aumenta de forma superior à linear quando mais nós são introduzidos em uma rede.
Tanto o Spark quanto o Hadoop são tecnologias que evoluíram a partir do modelo de programação conhecido como MapReduce, inventado dentro do Google em 2004, sendo que o Hadoop utiliza esse modelo de forma mais explícita, enquanto o Spark abstrai alguns dos conceitos e faz algumas adaptações. O MapReduce pode ser encarado como um paradigma de programação que permite uma grande escalabilidade, de forma que um processo possa ser dividido em diversos pedaços independentes, que serão atribuídos a diferentes nós (núcleos de um mesmo computador ou até mesmo de um cluster), e depois reagrupado.
O processo MapReduce pode ser divido em duas grandes etapas de tratamento de dados: a etapa Map do processo engloba as funções que converterão os conjuntos de dados de entrada a um conjunto de dados de saída, como por exemplo associando um par valor e chave. Na etapa Reduce a saída do Map é combinada em conjuntos menores de tuplas, reagrupando os resultados, permitindo a conclusão de resultados em cima do conjunto inicial de dados, como somar conjuntos de mesma chave. Além das duas grandes etapas, existe também uma etapa intermediária chamada Shuffle, que é responsável por mover a saída da etapa Map para a entrada da etapa Reduce. É importante ressaltar que os nós responsáveis pelo processamento de um determinado subconjunto de dados na etapa Map não necessariamente serão os mesmos nós responsável pelo processamento desses dados na etapa Reduce.
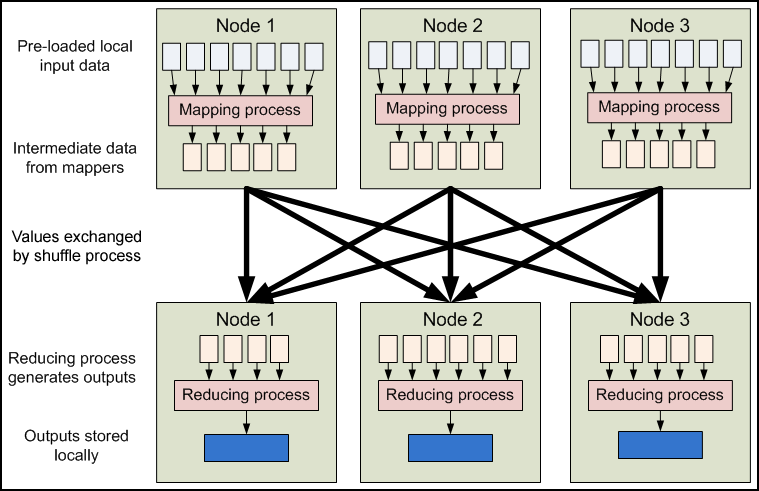
Figura 3.2: Esquema de funcionamento do processo de MapReduce
Fonte: https://developer.yahoo.com/hadoop/tutorial/module4.html#dataflow
Para que esses processos possam funcionar de maneira paralela, é utilizado o paradigma de programação funcional. O principal conceito desse paradigma é de que todo dado deve ser imutável; se alguma operação precisar ser feita nos dados, isso é feito gerando um novo conjunto de dados de saída e não alterando os dados de entrada.
Com a utilização de métodos de Big Data se torna possível o uso do grande conjunto de dados gerado constantemente pela Cidade Inteligente, associado a outros conceitos aqui descritos. Através da análise desse conjunto pode-se gerar informações e conhecimentos úteis para a melhora da qualidade da cidade e tomada de decisões mais inteligentes. O papel do Big Data é fundamental dentro de uma sociedade plenamente conecta com diversas tecnologias e dispositivos geradores de dados.
e-Government (Governo Eletrônico)
Governos atuais em todo o mundo estão enfrentando o rápido desenvolvimento da tecnologia da informação e comunicação. O Governo Eletrônico pode ser definido como o uso da tecnologia, em especial de aplicações web, para melhorar o acesso aos departamentos da cidade e os sistemas de gestão para cidadãos, parceiros de negócios, funcionários, agências, e outras entidades. Esse novo modelo faz uso da chamada Web 2.0, composto por aplicações de rede baseadas em tecnologias e princípios para explorar modelos de negócios web, bem como facilitar o desenvolvimento baseado na comunidade e redes sociais.
Os benefícios desse modelo podem expandir conforme o uso dos diferentes aspectos possíveis. O objetivo de um bom Governo Eletrônico é oferecer os mais variados recursos; além da disponibilidade de informações, a possibilidade de interagir e realizar transações com o governo. Com o Governo Eletrônico, a qualidade dos serviços prestados aos cidadãos e empresas pode ser melhorada significativamente e alcançar uma maior eficiência para todos. Além disso, inclui o feedback e engajamento de cidadãos interessados na possibilidade de novas aplicações e soluções para uma governança inteligente, promovendo uma melhor gestão e serviço através de sabedoria de massa.
A aplicação desse conceito requer uma mudança no gerenciamento dos dados, onde estes deverão ser disponibilizados para a população em meio online ou digital. Mesmo com agências governamentais encarando com receio a transparência dos dados, devido a questões como segurança e privacidade, existem casos de sucesso, como o governo do Canadá conseguindo grande engajamento dos cidadãos visitando o site do governo para consultas e transações, reduzindo custos e tempo gastos.